6.3 KiB
Kafka的文件存储原理
kafka 是一个分布式的缓存队列,文件存储时 将topic流数据进行分区存储(存放到多个broker节点),这样起到负载均衡、分布式并行处理的作用,因此具体存储的形式是 以
topic-partition形式命名的。
- 随着单文件的大小增大,检索效率降低,因此 参数
log.segment.bytes设置 单文件最大为1G,这意味着topic的一个分区也将分成多个segment,每个segment最大为1G,文件检索时效率更高。文件追加写入的策略是buffer满足4k,将数据写入*.log,并向*.index, *.timeindex写入索引 - kafka的写是追加写,这会跳过文件的检索步骤,kafka官网指出追加写入速率为
600MB/S,随机写速率为100KB/S,使得使用机械硬盘的性能不逊于固态硬盘。 - kafka的读,当读取对应topic的相应分区时,先通过segment来选择具体的读取文件,然后通过 offset向*.index 查询物理偏移量,再去*.log读取数据。此外,kafka实现零拷贝,使得数据无需在用户缓存空间进行传递拷贝,仅需要复制到内核缓冲区,然后发送到网卡,省去两次拷贝的开销
文件的清理
kafka时一个分布式的缓存队列,它的数据不像HDFS那样长期存储,kafka默认会将存在7天的过期数据进行删除。
log.cleanup.policy, 可选为 delete、compact,默认是deletelog.retention.hours默认 167 ,7天时间过期log.retention.bytes默认 -1 ,分区内的数据最大值,默认没有限制log.segment.bytes,默认1073741824 , 分区内的segment的最大值,默认为1Glog.cleaner.interval.ms,默认为 30000 ,5 分钟,这个参数适用于所有日志清理策略,包括删除(log.cleanup.policy=delete)和压缩(log.cleanup.policy=compact)。 如果log.cleanup.policy = compact,这不会删除过期数据,而是将重复建的记录进行合并,仅仅保留最新的记录,旧的记录将被清除。因此每个键在压缩后的日志中是唯一的最新值。需要配合使用下列参数log.cleaner.enable=true启用日志压缩功能。log.cleaner.min.cleanable.ratio定义清理的最低比例。即当未清理的数据量超过指定比例(默认 0.5)时,Kafka 会触发压缩。log.cleaner.backoff.ms,默认15000, 当 Kafka 完成一次日志压缩后,等待指定时间后才会执行下一次压缩。
kafka的监控
kafka-console-ui 下载
unzip kafka-console-ui.zip -d /usr/local/
cd /usr/local/kafka-console-ui bin/start.sh
bin/start.sh
访问localhost:7766,点击最右边的运维,添加集群信息
Kafka集群动态添加节点

Kafka的选举机制
controller选举
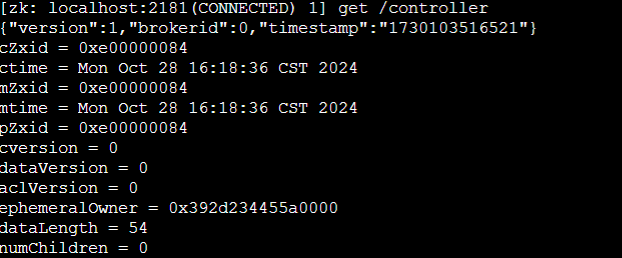
各个broker节点会向zookeper的 注册/controller节点 ,如果注册了这个节点,这个broker就是 controller节点
当 controller broker 宕机时,Zookeeper 会检测到 /controller 节点的会话过期,并自动删除该节点。
其他的 broker 都会监听该节点的变化,一旦监听到/controller节点被删除,brokers 会竞相尝试创建新的 /controller 节点》
partition leader选举
topic存在多个分区,而这每个分区又存在副本,这些副本之间有主从关系,为主从分区。主分区负责处理读写请求,从分区从 Leader 副本同步数据,确保数据冗余和容错。
集群的/controller的broker节点有controller组件,他会进行主从分区的选取,形成一个ISR(动态副本集)
- 问题:如果
topic的主分区所在节点宕机,需要从ISR中重新选举主分区,这个选举是顺序性的,最大程度保证和宕机的leader的最新数据是同步一致的。controller会协调这个选举过程,一旦检测到leader没有heartbeat,认为其宕机,立即选取新leader,并将zookeeper和broker的元数据进行更新,保证topic分区可用 unclean.leader.election.enable:当设置为true时,允许非 ISR 副本成为 Leader;当设置为false时,仅允许 ISR 中的副本成为 Leader(默认值为false,即不启用非 ISR 选举)
Kafka的数据同步
上述说到了topic的主分区宕机之后的leader选举,此时还需要进行分区数据的同步,选举出新的leader分区将自己的数据完整地同步到follower分区
- 情况一:就是当从分区正在同步主分区的数据,但是此时leader宕机,从分区的数据对于宕机leader的数据来说是不完整的,那么只能从
ISR中选择第一个,数据最新的从分区为新的主分区,然后进行数据的同步 - 情况二:就是宕机的是从分区
broker节点,这不会影响集群的运行,会将从分区从ISR中去除,如果从分区的broker恢复过来,从分区会向主分区同步,并重新加入ISR
Kafka的数据均衡
Kafka的一些
broker因为leader的频繁选举导致负载较重,此时可以进行分区再平衡,Leader 分区转移为 Follower 分区,从而减少该节点的压力。
我们可以选择关闭Kafka的leader平衡管理,改为自动管理。
auto.leader.rebalance.enable,默认为true,集群自动管理leader的切换选举
leader.imbalance.check.interval.seconds,默认300,集群检查是否选举切换leader的间隔时间
现在我们关闭集群的leader平衡管理,使用手动管理
- 直接指定
topic的leaderkafka-leader-election.sh --bootstrap-server nn1:9092 --topic topic_a --partition 1 --election-type preferred
- 也可以手动生成均衡计划
```bash
# 首先创建一个topic.json 输入如下内容 填写需要均衡的分区
{"topics":[{"topic":"topic_a"}],"version":1}
# 使用这个均衡优化命令生成优化计划
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --broker-list 0,1,2,3,4 --topics-to-move-json-file topic.json --generate
# 将上述命令生成的优化计划 编辑为 reassignment.json
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --execute --reassignment-json-file reassignment.json
# 验证是否重新分配成功
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --reassignment-json-file reassignment.json --verify